


当前文章是旧版蓝奏云批量下载的实现思路,仅供参考
新版实现思路和源代码都是需要打赏才能获取,详情请访问蓝奏云批量下载工具新版源码
获取软件的请访问蓝奏云批量下载工具
涉及知识
- Java的IO流
- Java的下载文件
- HtmlUnit的使用方法
- okhttp的使用
分析与软件思路
在某一天,我找到了一部电子书的资源,但是,该蓝奏云地址是一个文件夹,由于蓝奏云不支持批量下载,所以我便是诞生了打造出一个批量下载的工具的念头,大概搞了五天吧终于是成功了,折腾其中的重定向下载就搞了两天,说多了都是泪啊...
按照顺序,一步步分析吧
首先,我浏览器打开了蓝奏云地址,这里有两种情况,一种是有提取码,一种是没有提取码的。
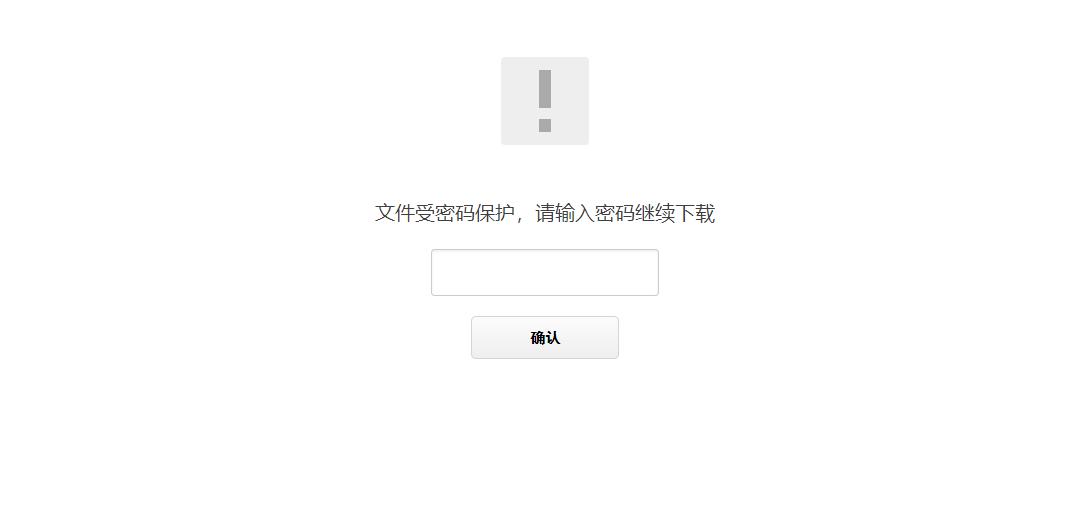
这个时候,我们需要可以自动模拟用户进行提交表单的操作**(代码详情见关键代码部分1)**
经过网上的查找,发现了HtmlUnit这个开源库可以实现我们需要的操作。
HtmlUnit,说白了就是一个浏览器,这个浏览器是用Java写的无界面的浏览器,因为其没有界面,因此执行的速度还是妥妥的
之后我们便是来到这样的界面
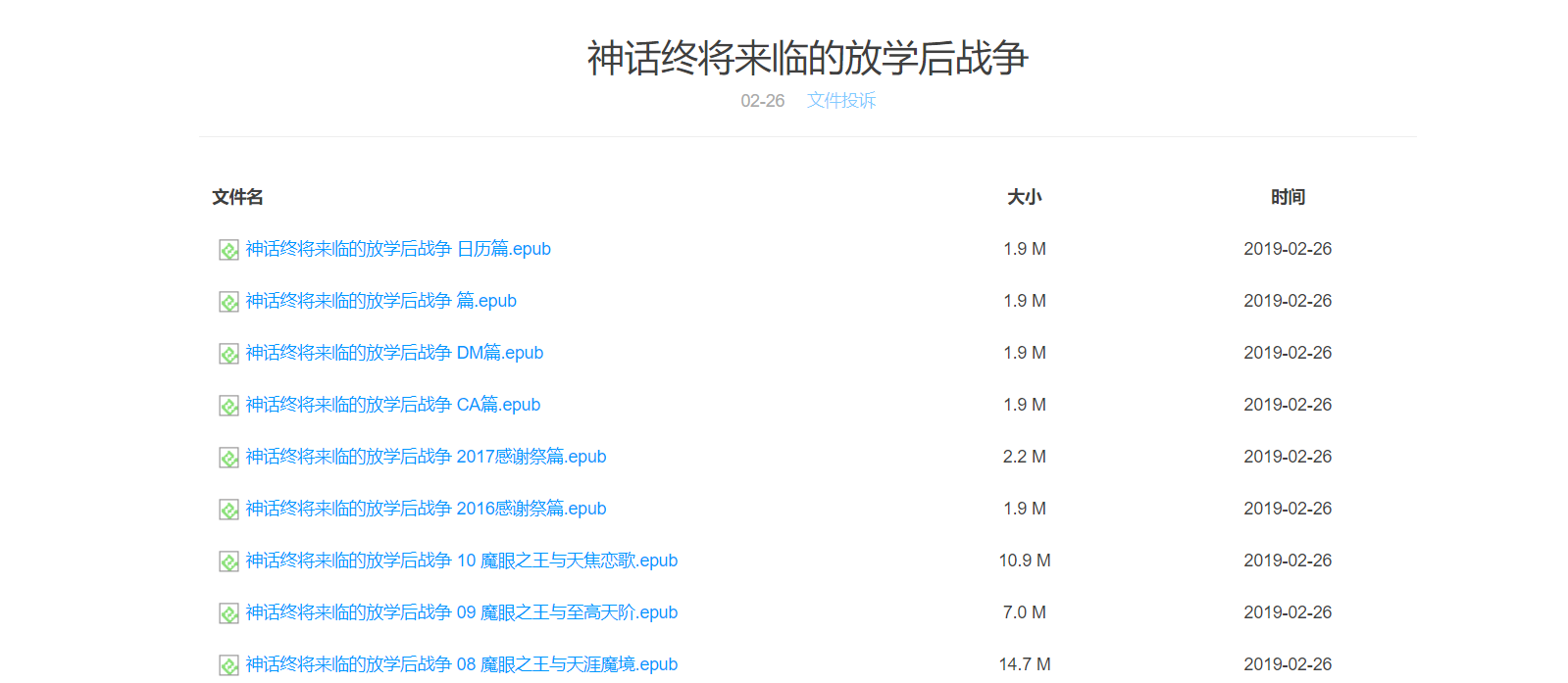
我们需要解析当前并获得每个文件对应的蓝奏云地址,这里由于HTMLUnit内置了html元素选择器,我们可以使用HtmlUnit的选择器进行节点的过滤操作,得到文件信息以及对应的蓝奏云地址**(代码详情见关键代码部分2)**
对了,这里有可能文件过多,会出现显示更多的按钮,这个情况我们也得考虑,我们可以使用HTMLUnit实现自动点击显示更多的按钮,我之前拿别人的链接来测试,那位大佬的链接里文件过多,导致我程序跑了二十多分钟,还没有跑完,然后,我的IP就被蓝奏云封了,出现了拒绝访问的警告。。
之后我重启了路由,由于IP地址是自动分配的,改了IP地址就解决了
所以,我打算限定一个最大的次数,超过之后就不点击了,即使列表还没有显示完全**(代码详情请见关键代码部分3)**
由于我们打开某个文件的蓝奏云地址,可以发现下载地址

右键,复制地址,我们得到下面这一串长长的链接,这个链接其实不是真实地址,所以,我姑且以伪直链来称呼它,伪直链的是具有时效性的,就是说会过期,所以,得尽快通过伪直链来获取真实地址。
https://vip.d0.baidupan.com/file/?AGYFO1tqDj9TWgE5VmNUOFFuVGxW7gKlAZhTvVCjVckJ7gLuANVV5AnvV4dQ4gCcAf5Ss1K1B7EE5AGdUopVsgCUBexb4w73U6MBslaSVNtR7VTZVpEC5AG8U9xQLFWyCZ4C8AC4VY8J2VfmUKsAhgF1UjJSfQdwBGEBIVJoVT0AbAU3W1kOM1NhAWpWNVRkUTJUZVY/AjUBMVNzUGpVJwk0AmcAbVUxCWlXMFA9ADcBfVInUn0HOAQxATdSP1VtAC8FYls0DnVTNwFhVi1UY1FoVGhWMAJiATVTM1A7VWQJbQJkAD9VNglrVzRQNgAxAT5SNFI6BzIEMgEwUjZVZAA4BWJbNQ4+UzcBZlZnVHtRblQhVnwCYgEgUyBQf1UxCXsCPAA5VTwJZ1c2UDAAMwFqUmFSKwdxBGoBalJrVTIAPQVjWzMObVM8AWNWMVRjUTlUZFYxAi4BIFMgUHxVaQk4AnsAe1VnCTNXdlA5ADABblJgUjQHNgQ3ATNSPlVmADQFdFtzDipTcgFqVjNUYFE+VGBWOAI4ATFTZFA0VWEJLwIgADRVcQliVzBQNQA2AXVSZlI1BzYELQE1Uj5VZgAuBWdbNg==
原本以为使用HtmlUnit开源库可以很简单地获取伪直链,不过,出了点状况,通过浏览器的元素审查功能,发现下面的那三个地址其实是一个iframe
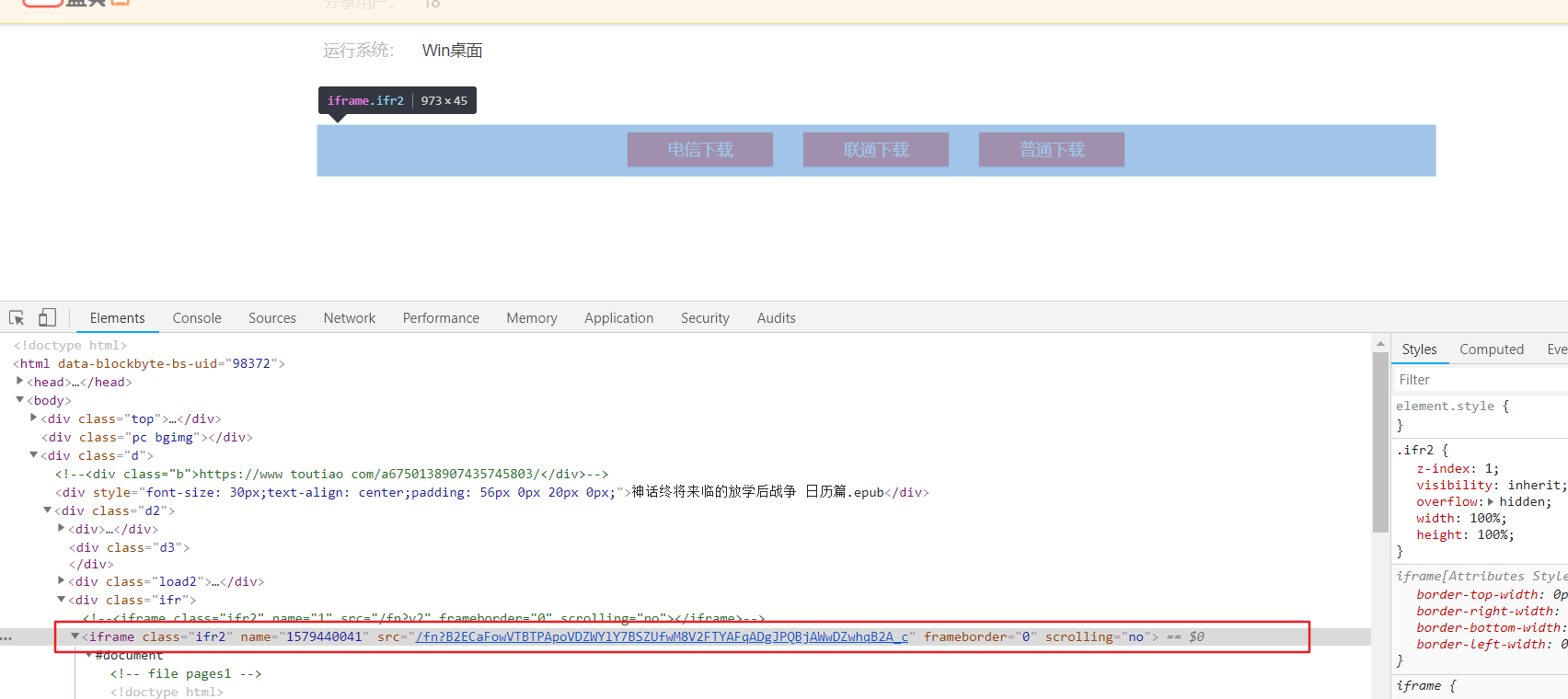
由于是iframe,相当于再次加载了另外一个页面,所以我们不能直接获得伪直链,得先通过获得iframe的src属性去访问它原本的那个网页。
我们可以通过浏览器,直接去访问那个页面(页面地址为https://www.lanzous.com+src属性值),页面打开如下:

页面需要等待一会,之后出现了三个按钮,之后,我们便可以获得a标签的href属性,即获得了伪直链的地址**(代码详情请见关键代码4)**
使用浏览器打开伪直链,浏览器会直接下载文件了,但是,在程序中使用Java的下载操作确实返回的html文件,内容较多,省略了一下样式,内容如下:
...
<div id="pwdload">
<div class="title">下载文件</div>
<div class="txt">系统发现您网络不正常,需要验证<br>请输入右边图形中的数字</div>
<div class="imcode"><img id="img" src="imagecode.php?" onclick="changeCode()"/></div>
<div class="cl"></div>
<div class="input_box"><input type="text" name="code" class="input" id="code" value="" /></div>
<div class="cl"></div>
<div id="pwderr"></div>
<div id="sub" onclick="down_r();" class="btnpwd">验证并下载</div>
</div>
<div id="info">
<div class="info1"><div class="info2"></div></div>
<div class="info3">恭喜你,通过了</div>
<div class="load" id="go">
</div>
</div>
...
</html>
这里研究了两天,终于是找到了别人的博文中找到了答案,原因是请求并没有携带请求头,所以导致蓝奏云返回一个验证的页面,有请求头的话, 就会重定向到真实的地址。
这里,我使用了okhttp这个开源库,实现添加了请求头,最后获得了真实的下载地址**(代码详情请见关键代码5)**,由此地址我们再调用Java中的下载即可成功下载该文件
关键功能代码及说明
1、2、3这三个部分的代码都是在MainController类中的download方法中
4、5部分在MainController类中的getDownloadLink方法中
这里我只抽取关键部分来进行讲解
1.模拟用户提交表单
注意,提交表单之后需要等待2s来等待js执行完毕以显示出文件列表
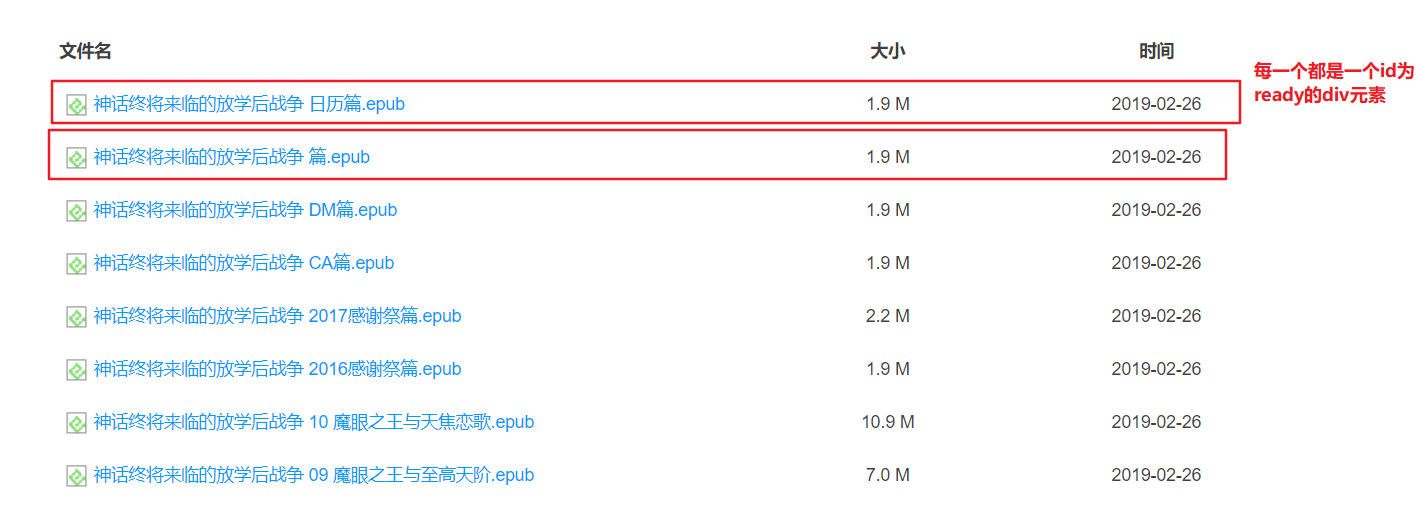
//这个readyNodes包含所有id为ready的div一个列表
val readyNodes = if (password.isNotBlank()) {
//有密码的情况
val pwdInput = page.getElementByName<HtmlTextInput>("pwd")
val button = page.getElementsById("sub")[0] as HtmlSubmitInput
pwdInput.valueAttribute = password//输入提取码
val finishPage = button.click<HtmlPage>()//提交表单
webClient.waitForBackgroundJavaScript(2000)//等待2s
finishPage.getElementsById("ready")
} else {
//无密码的情况
webClient.waitForBackgroundJavaScript(2000)
page.getElementsById("ready")
}
2.自动点击加载更多按钮
//文件可能不止一页,为了防止被封IP,限定最大翻页数,由用户输入
for (i in 0 until pageCount) {
if (page.getElementById("filemore") != null) {
page = page.getElementById("filemore").click()
} else {
break
}
}
3.解析列表获得各文件对应地址
为了方便,我直接把文件名、日期等参数也一并获取了,用了一个ItemData的bean类进行数据的存储
//初始化列表(分享的蓝奏云地址中的所有文件及相关信息)
val itemDatas = arrayListOf<ItemData>()
//选择器进行网页的解析获取数据
for (readyNode in readyNodes) {
val childNodes = readyNode.getElementsByTagName("div")
val nameNode = childNodes[0].lastElementChild
val sizeNode = childNodes[1]
val timeNode = childNodes[2]
val name = nameNode.textContent
val link = nameNode.getAttribute("href")//单个文件的蓝奏云地址
val size = sizeNode.textContent
val time = timeNode.textContent
itemDatas.add(ItemData(name, link, "", size, time))
}
4.获得伪直链地址
//url是单个文件的蓝奏云地址
val page = webClient.getPage<HtmlPage>(url)
val srcText = page.getElementsByTagName("iframe")[0].getAttribute("src")
//拼接字符串,得到另外页面的url
val downloadHtmlUrl = "https://www.lanzous.com$srcText"
val downloadPage = webClient.getPage<HtmlPage>(downloadHtmlUrl)
//等待js加载完毕
webClient.waitForBackgroundJavaScript(1000)
//获得伪直链地址(a标签的href属性值)
val address = downloadPage.getElementById("go").firstElementChild.getAttribute("href")
5.使用okhttp获得蓝奏云真实地址
HttpUtil.sendOkHttpRequest(address, object : Callback {
override fun onFailure(p0: Call?, p1: IOException?) {
println("error")
}
override fun onResponse(p0: Call?, response: Response?) {
itemData.downloadLink = response?.request()?.url().toString()
response?.close()
}
})
//补充的okhttp的工具类HttpUtilsendOkHttpRequest的方法
fun sendOkHttpRequest(address: String, callback: Callback) {
val client = OkHttpClient()
val control = CacheControl.Builder().build()
//添加请求头user-agent和accept-language
val request = Request.Builder()
.addHeader("user-agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36")
.addHeader("accept-language","zh-CN,zh;q=0.9")
.cacheControl(control)
.url(address)
.build()
client.newCall(request).enqueue(callback)
}
6.下载功能
虽然和之前的工具一样,但是我还是把代码贴出来吧
/**
* 下载文件到本地
* @param url 网址
* @param file 文件
*/
private fun downloadFile(url: String, file: File) {
if (!file.exists()) {
val conn = URL(url).openConnection()
conn.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)")
val bytes = conn.getInputStream().readBytes()
file.writeBytes(bytes)
}
}
PS:我在解析过程和下载过程中使用了多线程下载,提高了速度。具体实现思路请参考之前我的这一篇文章打造m3u8视频(流视频)下载解密合并器(kotlin)的第4部分
评论区